About two years ago I wrote about replacing text in the DOM, and how “it’s not that simple“. I revisited the problem a couple days ago and found a novel solution.
What is the problem? The problem is very simple. You have a DOM element, like:
<p> This is a test. Testing is fun! </p> |
You want to wrap all instances and variations of the word “test”, like so:
<p> This is a <span class="f">test</span>. <span class="f">Testing</span> is fun! </p> |
In other words we need to match that element’s text content against the regular expression /btestw*b/gi (any words beginning with “test”). Not only do we need to match but we also need to replace. Replacing in the DOM can’t be done as a simple string operation like:
element.innerHTML = element.innerHTML.replace( /btestw*b/gi, '<span class="f">$0</span>' ); |
Actually, this will work, but it has the following caveats:
- It doesn’t guarentee that you’re only replacing text between HTML tags.
innerHTMLcontains all HTML so you could be replacing thetest123in<br class="test123"/>, or any other text between<and>. - The replacement completely wipes any inner elements from existence. This means any prior references to those elements are useless and event listeners will be gone. There will still be elements, but they’ll be fresh elements, not the ones from before.
Caveat #1 can be avoided by only replacing what we get from innerText (or textContent):
element.innerHTML = element.innerText.replace( /btestw*b/gi, '<span class="f">$0</span>' ); |
Apart from the cross-browser issues innerText/textContent have, this solution also has a massive problem. It totally disregards any actual HTML that was previously in the element.
Current solutions
Current solutions tend to traverse through all child text nodes, individually testing them for matches, and then splitting the actual text-node into separate parts, wrapping the matched part in an a new element.
This is, without a doubt, a far better solution than the innerHTML/Text stuff above, but there are still caveats:
These solutions tend to assume that adjacent text nodes cannot exist, and it’s true that they rarely do but if they’ve been dynamically added it’s quite rare that the guilty developer will have remembered to call Node#normalize.
Most importantly, what happens if a match spreads across various nodes?? For example:
<p> This is a te<em>st</em>. </p> |
I haven’t yet found a solution that takes these cases into account. A correct solution would transform the above into something like:
<p> This is a <span class="f">te<em>st</em></span>. </p> |
Or, perhaps:
<p> This is a <span class="f">te</span><em><span class="f">st</span></em>. </p> |
i.e. wrapping either the entire match, including intersecting elements, or matching individual portions of the match.
Why is it tricky?
To match that initial regular expression we need a single chunk of text we can test against. If we test each individual text node then we won’t get any matches for the above. "te" is one text node, and "st" is another.
Replacement is also a hassle, because you’d have to split the matched node(s) at the right place and wrap in one or more replacement elements. It’s not a simple operation anymore, and probably costs more than its worth in developer time.
Here are the requirements for solving the “problem” correctly and fully:
- Must accept and work correctly with any regular expression valid in JS.
- Must be able to match across element bounderies. For example, it must be able to match
appleinapp<em>l</em>eand even in<em>What is app</em>le! - Must not be destructive to element nodes. Destroying/splitting/normalizing text nodes is permissable though.
After trying a few different variants, one including injecting tokens into innerHTML in order to locate the matching nodes, I landed on one which is relatively efficient and seems to work well!
How is it done?
targetElement = where we’re looking for our matches.
- Collect aggregate text of targetElement by using something like this (avoid innerText/textContent).
- Match text against regular expression, collecting the start and end indexes of every match.
- Traverse through the targetElement’s node tree, incrementing a counter to keep track of our text-index location. When we meet a match’s location then grab the start-node, the end-node and any intersecting nodes and send them to step #4.
- With the custom DOM range details (start-node, intersecting-nodes, and end-node):
- If the start-node is the same as end-node, then split the node into three parts. Before-match, match, and After-match. Then wrap match in
<span class="f">. - If the start-node is different to end-node, then split each of them into match and non-match parts, wrapping the matching parts in
<span class="f">. Also wrap any intersecting text nodes.
- If the start-node is the same as end-node, then split the node into three parts. Before-match, match, and After-match. Then wrap match in
New: findAndReplaceDOMText
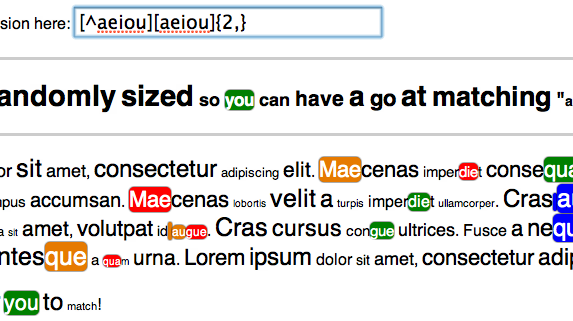
Spooky message in the first three highlighted words!! D:
Using the steps above I wrote findAndReplaceDOMText which allows you to wrap regular-expression matches found in DOM text in any element you want. If matches are split across multiple nodes it will wrap each portion individually. Please check out the demo!
Thanks for reading! Please share your thoughts with me on Twitter. Have a great day!
Just a heads-up; you’ve got a typo in “Node#noramlize”. 🙂
Luke
Not so much a problem of replacing text in the DOM, but getting rid of any HTML tags that interfere with the text you want to read. One solution to this is using something like HTML Purify, or one of the many other tools that strip markup from HTML documents.
The only caveat here, is most of the solutions are server-side, and I think you main gripe in this article is not being able to do it client side, without much fuss.
And that’s fine. However, I live by the idiom, server-side first, then worry about the client-side.
Client-side zealots will berate me for this statement, but it is a pattern that doesn’t seem to stop.
Hey James,
I’ve done something similar you might be interested in 🙂
http://blog.vjeux.com/2011/project/world-of-warcraft-html-tooltip-diff.html
@David: the canonical use case for this is (live) search text highlighting, like in the screenshot at the end. That is a client-side concern, and it might be affecting a complex HTML tree, with existing event handlers, or even generated by third-parties. In this case stripping mark-up is the last thing you want to do.
This is pretty awesome. Being able to manage node boundaries is often overlooked. 🙂
Very nice approach, bookmarked it!
@David Higgins: I hope you don’t mean to say you need a server to replace a text inside a html-document..? Why would you use another computer if the client can do that job? I think servers should do things clients can’t, or should be hidden from clients.
I’ve done a fair amount of work in a very similar area recently for my Rangy library. It goes further by working on “the text the user sees”, i.e. not considering text that is hidden by CSS or is within a script or style element, collapsing consecutive spaces, includes line breaks generated by br elements and block elements. Here’s a demo:
http://rangy.googlecode.com/svn/trunk/demos/textrange.html
The relevant part is the custom search feature.
xpath is helpful. The Javascript will replace all occurances of ‘the’ with ‘ye’.
javascript:d=document;x=d.evaluate(‘.//text()[normalize-space(.)!=”]’,d.body,null,7,null);for(i=0,l=x.snapshotLength;i<l;i++){t=x.snapshotItem(i); t.data=t.data.replace(/the/gi,'ye')} void(1)
@Mark, re: server versus client concerns. There are good reasons to do things on the server even though the client *can* do them, or the server doesn’t *need* to do them.
Maybe it’s just easier. Writing and debugging is almost always easier on the server, because it’s completely under your control, and chances are you’re using a framework with a lot more built in than client-side javascript. If server load is not a concern, and for most people it isn’t, then there’s a very real value to coding something in a way that takes less time and is easier to maintain. Let’s face it- Javascript is an interesting language, but it sure doesn’t come with a lot out of the box compared to your typical server framework.
And, it’s less code you need to send over the wire to the client.
Thanks for your solution.
The event handlers are not problems. Usually you have a function which initialize your handlers. After replacing, I am able to reattach the handlers. If you use delegation pattern you could avoid reinitialization.
This is nasty, isn’t it? HTML formatting only of couple of symbols in the word. Anyway, you could strip formatting tags such:
em,b,strong,iI haven’t seen someone to attach handlers of formatting tags and I don’t want to see.
After that the solution is really simple and I guess faster than DOM manipulations.
If someone is interested in my solution I will post the code.
So this isn’t quite the same, we had a project that you could include a script tag and it would find all occurrences of the word “red” stand alone or inside other words (like ordeRED) and create a link out of it, style it leave the word looking like orde(red) (where “(red)” is styled and the link).
Thought I’d share it with you – basically what it does is look for specific tags, and drives down to the #text node, and once it has that, mash away at the content to create the modified DOM: http://remysharp.com/downloads/red.js (authored back in 19 Oct 2008!).
James,
Thanks for this article. It has helped me a lot, including the “traversing nodes to search for a text” thing.
I’m writing a GWT library that uses the same principles you’ve described here.
Thanks for sharing this.
Best regards!
Just tested your fantastic script via the demo with this sample text:
“In this condition, I will succeed.”
This was a straight paste from word, but it is not finding the text due to the ” ” html special character when trying to match “condition, I”
Sorry it is me again, the white space was a non breaking space, and I did not place it in a markup, so here we go again:
@Gyorgy, You’ll need to modify the regular expression that you search with to include
. E.g. If I was searching for the text ‘foo bar’, and the space in between were potentially a non-breaking space, then I’d have to search instead for/foo(?:s| )+bar/.Appreciated James, yes replacing & nbsp ; with s works great! Much appreciated.